Everything I’ve Learnt About Distributed Locking So Far
In this post we are going to be looking at locking in a distributed system. But, first let us go back to the basics and remind ourselves what is a lock is and why we need locks.
What is a lock? Why do we need it?
In computer science, a lock is a synchronization mechanism that is used to control access to a resource when there are multiple threads of execution. Locks are used to guarantee mutual exclusion, i.e., only one thread of execution can be inside a critical section at any given point in time. At a very high level we make use of locks to achieve correctness in a multithreaded environment.
In order to understand locks further let us look at an example: Consider a singly linked list that contains four items, namely “i – 1, “i”, “i + 1” and “i + 2” as shown in the diagram below:

This linked list is being shared by two different threads of execution. At time t0, the first thread wants to remove node “i”, so it changes the “next” pointer of node “i – 1” to point to node “i +1” as shown in red. At the same time instant, t0, the second thread of execution wants to remove the node “i + 1” and hence it changes the “next” pointer of node “i” to point to node “i + 2” as shown in blue.
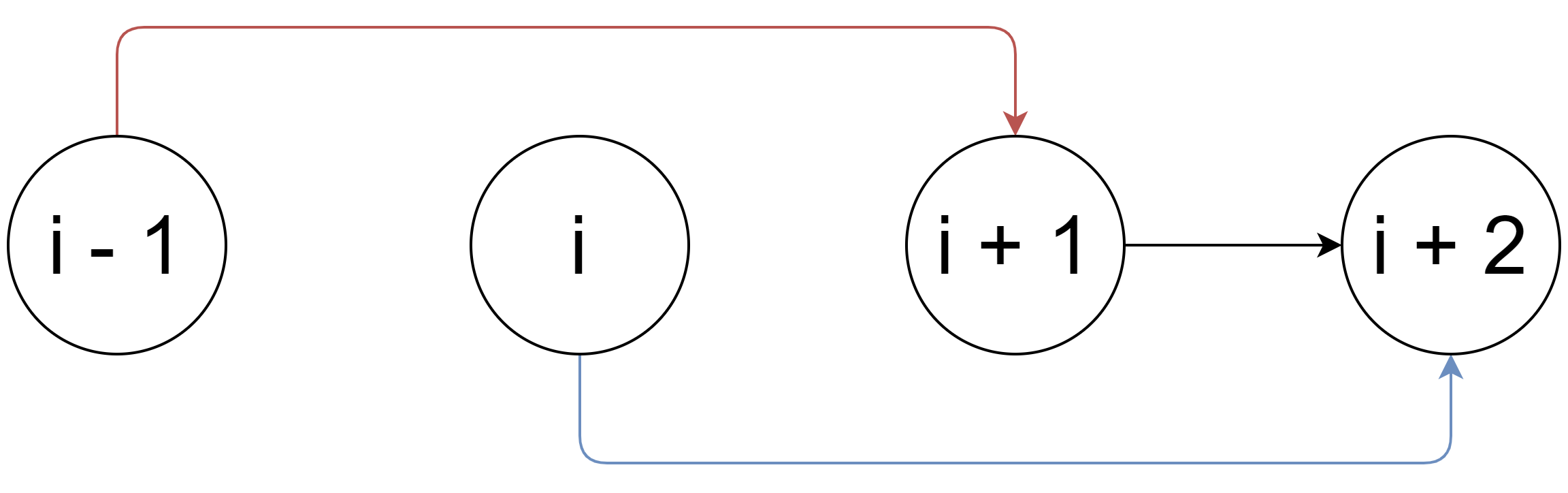
At time instant t1 > t0, the state of the linked list will be:

Even though the remove operation was performed twice on the linked list, we ended up removing only one element. Our desired state of the linked list has not been achieved. This problem is commonly known as a race condition. To solve the race conditions, we need to make use to mutual exclusion (by extension locks) to ensure that simultaneous updates cannot occur.
Distributed Locking
In the previous section we looked at why locks are important to ensure correctness of results. We also looked at an example of a linked list in a multithreaded environment in a single system, now let us look at how can we make use of a locks in a loosely coupled distributed systems to ensure correctness of results. But, first let us remind ourselves of the CAP theorem.
CAP Theorem
When designing distributed services, there are three properties that are commonly desired: consistency, availability, and partition tolerance. It is impossible to achieve all three. [1]
- Consistency: Every read receives the most recent write or an error
- Availability: Every request receives a (non-error) response, without the guarantee that it contains the most recent write
- Partition tolerance: The system continues to operate despite an arbitrary number of messages being dropped (or delayed) by the network between nodes
In a distributed system, a network partition is inevitable. Therefore, according to the CAP theorem, we must pick among:
- Cancel the operation and thus decrease the availability but ensure consistency
- Proceed with the operation and thus provide availability but risk inconsistency
Are networks really that unreliable? Yes.
A team from the University of Toronto and Microsoft Research studied the behaviour of network failures in several of Microsoft’s datacentres. They found an average failure rate of 5.2 devices per day and 40.8 links per day with a median time to repair of approximately five minutes (and up to one week). While the researchers note that correlating link failures and communication partitions is challenging, they estimate a median packet loss of 59,000 packets per failure. Perhaps more concerning is their finding that network redundancy improves median traffic by only 43%; that is, network redundancy does not eliminate many common causes of network failure.[2]
A joint study between researchers at University of California, San Diego and HP Labs examined the causes and severity of network failures in HP’s managed networks by analysing support ticket data. “Connectivity”-related tickets accounted for 11.4% of support tickets (14% of which were of the highest priority level), with a median incident duration of 2 hours and 45 minutes for the highest priority tickets and a median duration of 4 hours 18 minutes for all priorities. [2]
Google’s paper describing the design and operation of Chubby, their distributed lock manager, outlines the root causes of 61 outages over 700 days of operation across several clusters. Of the nine outages that lasted greater than 30 seconds, four were caused by network maintenance and two were caused by “suspected network connectivity problems.” [2]
Can other things go wrong in a distributed environment? Absolutely.
A network partition is only a small part of what can go wrong in a distributed environment. Some of the other things that can go wrong in a distributed environment include:
- A node can crash, or be rebooted by the orchestrator
- The service might become unresponsive for an extended period due to a super long GC pause
- Time synchronization issues
Goals
We have established that it is not possible for us to build a prefect distributed system and we must pick between availability and consistency. Let us now look at what is the main purpose of a distributed lock.
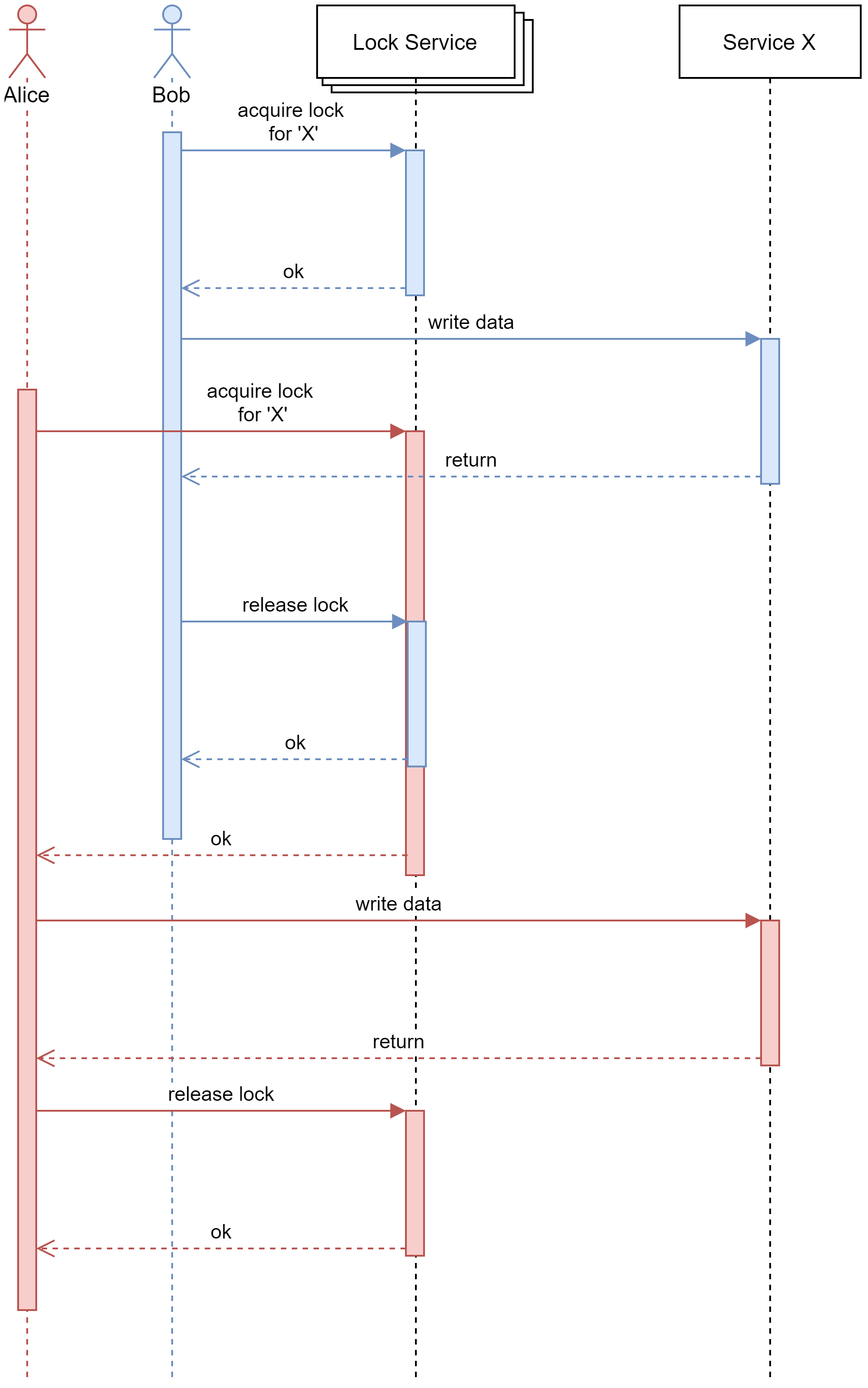
Both Alice (shown in red) and Bob (shown in blue) want access to Service X and a bunch of other services (not shown), so they first request a lock from one of the many lock service nodes and then they access “Service X” using the lock they acquired from the lock service. The lock service will ensure mutual exclusion for Alice and Bob for Service X and all the other services that would like access. Note: all the services must participate in the distributed locking mechanism.
Let us now start looking at how we can get distributed lock with a single instance of the lock service and then we can look at how we can horizontally scale the lock service.
Fenced locks
A fenced lock is a lock that includes a fencing token. A fencing token is a monotonically increasing token that increments whenever a client acquires the lock.
To understand why fencing tokens are necessary, let us look at what will happen when we do not have fencing tokens in a distributed system:
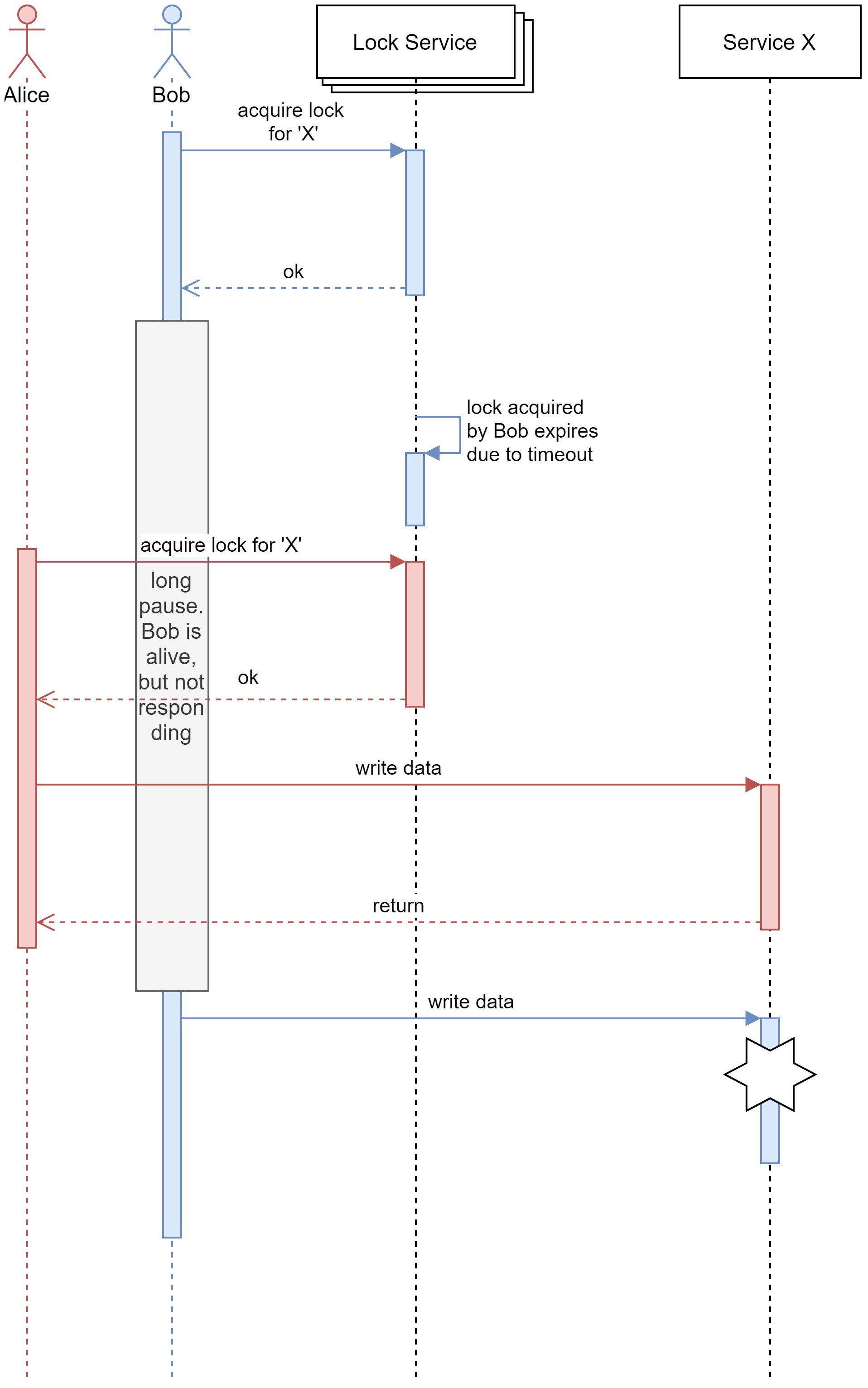
In the above scenario, Bob has acquired the lock, but due to some reason (bug in code, super long GC), Bob stopped responding for an extended period. When Bob was in a “hung” state, Bob’s lock has expired due to a timeout (Note: It is always good to have timeout for locks otherwise, a crashed client will lock out every other client). Alice acquired the lock the lock for service ‘X’ and made a change to service ‘X’. When Bob is back from the “hung” stage, he will now make an unsafe change to service ‘X’, because he still thinks he has the lock for the service. But, wait why can’t Bob just check if he still has access to the lock just before accessing the service? Yes, he can but that will also not work as Bob can go into an unexpected “hung” state at any time (It can be after he has made the check if has the lock).
Now, let us look at how we can solve this by making use of fencing tokens.
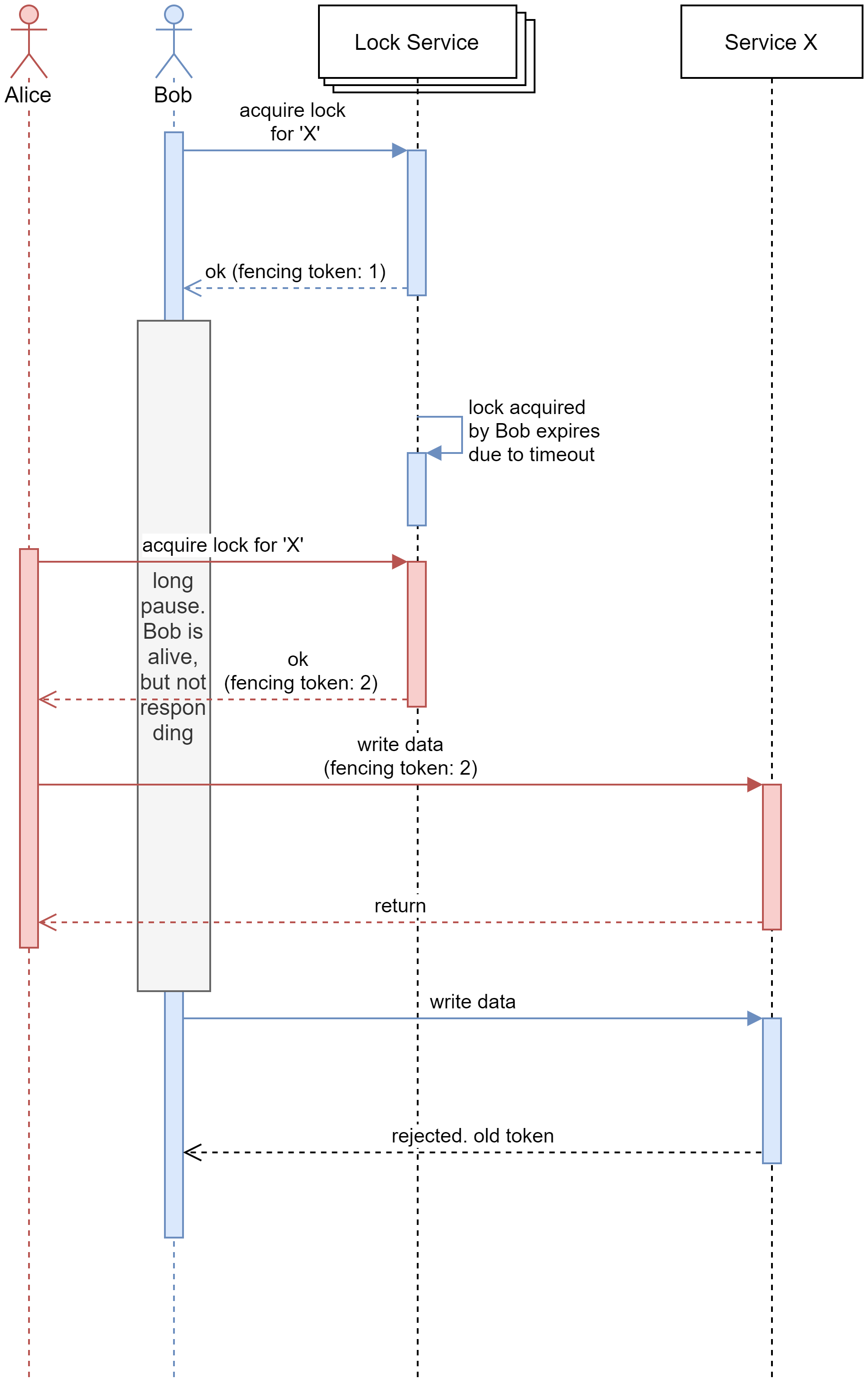
Now that we have fencing tokens, Bob acquires a lock and he gets a fencing token of 1. Just like in the previous scenario, he goes into a “hung” state. While Bob is in this “hung” state, his token times out. Alice comes online and acquires the lock. She is given a fencing token of 2. Alice passes her token (i.e., 2) to service ‘X’ along with her write request. The service stores Alice’s token as the last known token and it honours Alice’s request. Now, when Bob comes back from his “hung” state, he attempts to make a write request to service ‘X’ by passing his fencing token. The service checks the token passed by Bob against its’ last known token, finds out that the Bob holds an old token (remember, fencing tokens are monotonically increasing) and it will not honour Bob’s request.
Notice that it is no longer possible to make unsafe changes to service ‘X’ due to the monotonically increasing property of fencing tokens. And yes, this has made service ‘X’ linearized.
Now that we have a fair idea of a distributed lock, let us now look at how to make our lock service horizontally scalable.
Horizontally scaling the lock service
To horizontally scale the lock service itself we need to ensure that the service is always consistent while tolerating network partitions. This would mean that we are going to be sacrificing the availability of the lock service, i.e., in the face of a network partition, the lock service may decide to stop issuing locks till the partition is resolved. This is done so that we do not end up with a split-brain scenario.
Split-brain is a computer term, based on an analogy with the medical Split-brain syndrome. It indicates data or availability inconsistencies originating from the maintenance of two separate data sets with overlap in scope, either because of servers in a network design, or a failure condition based on servers not communicating and synchronizing their data to each other. This last case is also commonly referred to as a network partition.[3]
In the case of distributed locking, a split-brain scenario will become a nightmare because it will give two parties a “lock” on the same resource. If two parties can hold the same lock, we have fundamentally broken the definition of a lock. To avoid this, we pick consistency over availability.
To develop a consistent locking service that can tolerate network partitions each node should maintain the state of the lock along with the fencing tokens and it must achieve consensus using a consensus algorithm. You can either make use of the Raft consensus algorithm or the Paxos consensus algorithm. Raft consensus algorithm is easier to understand and is described below.
Raft consensus algorithm
Raft is a consensus algorithm that is designed to be easy to understand. It is equivalent to Paxos in fault-tolerance and performance. The difference is that it is decomposed into relatively independent subproblems, and cleanly addresses all major pieces needed for practical systems. [4]
I had planned on explaining the Raft consensus algorithm, but I found this beautiful visualization of the raft consensus algorithm here. I highly recommend that you check it out before proceeding. It very clearly explains how the algorithm behaves in a normal situation and during a network partition.
Conclusion
In this blog post, we had a look at one of the ways in which we can design a horizontally scalable distributed locking system that provides consistency (while sacrificing availability) while tolerating network partitions using fencing tokens and the Raft Consensus algorithm. This exact approach has been implemented by the Hazelcast team in their latest version of their in-memory data grid, please do check that our as well.
References
| [1] | S. Gilbert and N. Lynch, “Brewer’s conjecture and the feasibility of consistent, available, partition-tolerant web services,” ACM SIGACT News, vol. 33, no. 2, p. 51–59, 2002. |
| [2] | [Online]. Available. |
| [3] | Wikipedia, “Split-brain (computing),” Wikipedia, [Online]. Available. |
| [4] | “Raft,” [Online]. Available. |